More details can be found here.
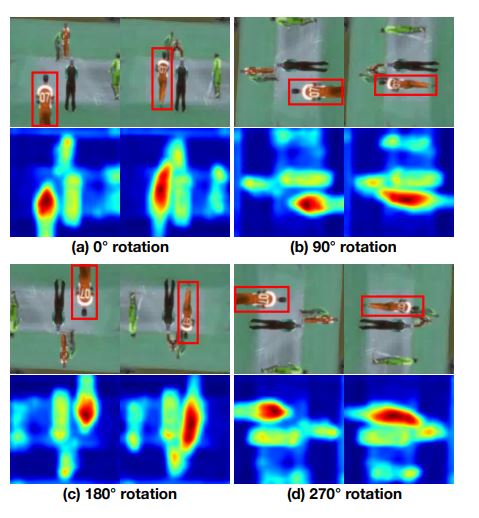
Video frames and their corresponding attention maps generated self-supervised 3DRotNet at each rotation. Note that both spatial (e.g. locations and shapes of different persons) and temporal features (e.g. motions and location changes of persons) are effectively captured. The hottest areas in attention maps indicate the person with the most significant motion (corresponding to the red bounding boxes in images). The attention map is computed by averaging the activations in each pixel which reflects the importance of that pixel.