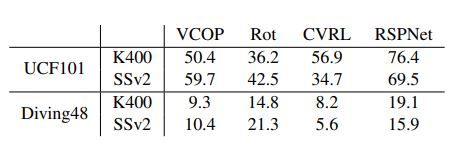
Table 1: Pretraining on K400 and SSv2 with 30k subset size, finetuning on UCF101/Diving48 using R21D network.
Looking into Table 1, VCOP and RotNet, outperforms the pre-training of K400 with SSv2 by a margin of 6-9% on UCF101, 3-6% on Diving48 dataset. In case of CVRL and RSPNet, pre-training with K400 than SSv2 outperforms on both UCF101 and Diving48. The best performance on UCF101 is from RSPNet pre-trained on K400, and, on Diving48, it’s RotNet pre-trained on SSv2.
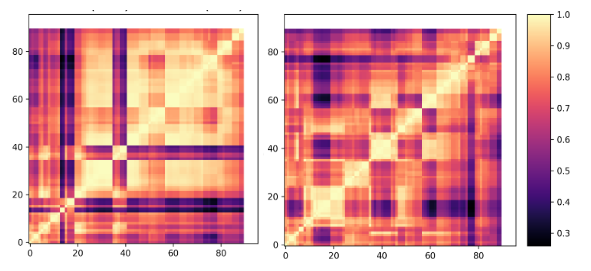
Figure 1: CKA maps for layer representations: Out of Distribution on VCOP and CVRL for R21D Network (Left to right).
R21D pretrained on K400 shows a semi-block structure for VCOP, indicating near-saturation condition of the network on this pretext task. It shows a more prominent grid-based structure on CVRL and RSPNet instead. These observations corroborate the quantitative results, where pre-training on K400 for both CVRL and RSPNet gives better performance.