Observations: With only 30k videos compared to 240k videos used by other pretext tasks, we show that our model outperforms by good margin on UCF101 against single and multi-modal approaches. On HMDB51, we have a comparable performance. TCLR effectively takes in a larger clip duration at pre-training stage, whereas, other approaches use a bigger frame size or more number of frames.
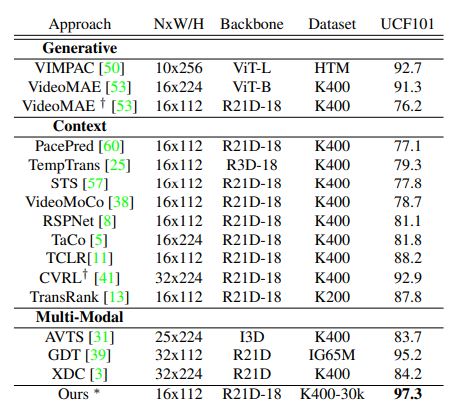
Table 1: Comparison with previous approaches pre-trained on K400 full set. Ours (*best performing) is RSPNet pretrained on 30k subset of K400. † represents model with different backbone than R21D. *reproduced results.